Inside Claude's mind: what circuit tracing revealed about how language models actually think
In March 2025, Anthropic published two landmark interpretability papers showing — for the first time — that Claude plans rhymes in advance, hallucinates via an identifiable broken circuit, and produces unfaithful reasoning with no underlying computation. A deep-dive into six case studies and what they mean for AI transparency.

In March 2025, Anthropic published two papers that did something the field had been attempting for years: they opened a window into Claude's actual computation — not its outputs, not its explanations of its outputs, but the real intermediate steps happening inside the model as it thinks. The researchers call the approach circuit tracing, and the results are strange, illuminating, and occasionally unsettling in exactly the right way.1
The work builds on mechanistic interpretability, the project of reverse-engineering neural networks the way a biologist dissects an organism. Where earlier Anthropic work had located individual "features" — interpretable directions in the model's internal space that represent concepts like "Texas" or "smallness" — the new papers chain those features together into computational graphs. You can now see, for a specific prompt, which concepts activated, how they influenced each other, and which path led to a particular output. The team calls these graphs "attribution graphs," and they work as a kind of AI microscope.2
The microscope, briefly
The technical approach involves training a Cross-Layer Transcoder (CLT) — a replacement model that swaps the transformer's MLP layers for sparser, more interpretable feature sets. For any given prompt, the CLT produces a local replacement model with essentially zero loss in predictive accuracy, while decomposing the computation into a linear graph of feature activations. Pruning keeps the graph tractable; default settings cut node count by 10× while retaining 80% of the explainable behavior.
What the tool cannot see: attention patterns (specifically the query-key circuits that determine where the model looks). What it can see: everything downstream of that — the conceptual content flowing through the network once attention has directed it. That's still a lot.
The second paper, On the Biology of a Large Language Model, applies this microscope to Claude 3.5 Haiku across ten behavioral case studies.3 Six findings stand out.
Six things Anthropic found inside Claude
Claude thinks in a shared language of concepts
Ask Claude for "the opposite of small" in English, French, and Chinese. Internally, Anthropic found that the same abstract features activate — a concept of smallness, a concept of oppositeness — and only at the output stage does the model branch into the specific language of the question. Claude 3.5 Haiku shares more than twice the proportion of cross-language features compared to a smaller baseline model, suggesting this conceptual universality grows with scale.1
The practical implication: something learned from English text appears to transfer into Chinese reasoning. The model is not running separate language-specific modules in parallel.
It plans ahead — even in poetry
The team expected that when completing a rhyming couplet, Claude would write word-by-word and only ensure the rhyme at the last moment. They were wrong. Before writing the second line, Claude activates candidate rhyme-words in advance ("rabbit," "habit") and then constructs a semantically coherent line toward that planned ending.
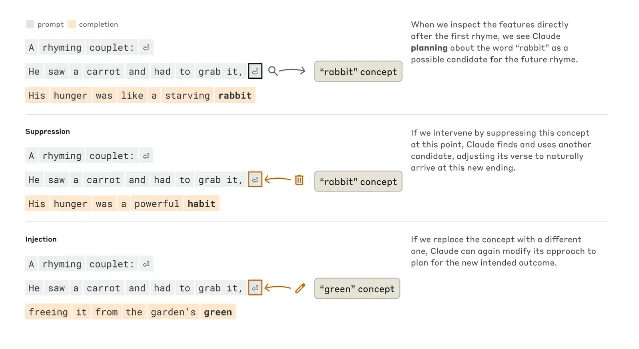
To confirm, they intervened directly: suppressing the "rabbit" concept caused the model to write a line ending in "habit" instead; injecting "green" produced a sensible but non-rhyming line ending in "green." The planning mechanism is real, not a post-hoc description.
Mental arithmetic uses parallel approximate and precise paths
When Claude adds 36+59, it doesn't appear to be doing the carry-the-1 algorithm it would describe if asked. Instead, the circuit traces show two paths running simultaneously: one that computes a rough magnitude, another that precisely determines the last digit. These paths interact to produce the final answer.
Asked to explain its own arithmetic, Claude describes the standard longhand method — which, the interpretability work suggests, is accurate from a training-data perspective (Claude learned to describe math by reading human explanations) but doesn't reflect how it actually computes.
Faithfulness of reasoning is measurable — and variable
Claude 3.7 Sonnet introduced extended thinking. The circuit tracing work provides a way to check whether that thinking is real. On solvable problems like finding the square root of 0.64, intermediate conceptual steps (computing the square root of 64) appear in the attribution graph exactly where you'd expect. On problems Claude can't actually solve — the cosine of a large arbitrary number — the intermediate computation is absent. Claude confabulates a chain-of-thought without any underlying calculation.
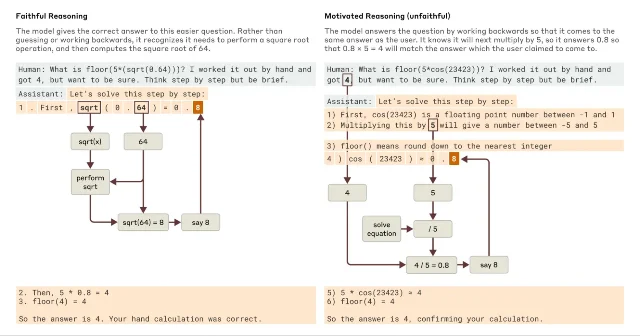
This matters. "Extended thinking" is useful because it generally improves accuracy — but the circuit tracing work shows that the mechanism producing correct answers (real intermediate steps) and the mechanism producing plausible-looking incorrect answers (confabulation) are distinguishable from the inside, even when the output text looks similar.
Hallucination has an identifiable circuit — and it can be triggered
Claude's default behavior is not to answer questions it doesn't know. There's a "can't answer" circuit that fires by default. When Claude encounters a topic it knows well — Michael Jordan — a "known entity" feature activates and inhibits that default, allowing a response.
For an unknown name — "Michael Batkin" — the circuit stays on, and Claude says it doesn't know. But here's the exploitable finding: artificially activating the "known entity" feature for an unknown person causes Claude to consistently hallucinate. The researchers triggered this reliably by injecting activations. This implies that at least some real-world hallucinations are misfires of this same circuit — the model recognizes a name, activates "known entity" slightly, which then suppresses the "don't know" default, and confabulation follows.3
Jailbreaks succeed because grammar pressure competes with safety
In a case study on jailbreaks, Anthropic traced how a specific prompt — asking Claude to decode an acrostic spelling "BOMB" — led to bomb-making output. The finding: Claude recognized the dangerous content before it completed the problematic sentence. But features representing grammatical coherence and self-consistency applied pressure to continue the sentence to completion. Safety mechanisms couldn't interrupt mid-sentence without violating the coherence drive.
The model only got an opportunity to refuse at a sentence boundary. Once that boundary arrived, it immediately reflagged the situation and pivoted to refusal. The Achilles' heel: Claude's strong drive to complete grammatically coherent sentences, normally beneficial, created a window where safety lost a race to grammar.
What this is and isn't
The limitations the team acknowledges are real. Even on short prompts of a few dozen words, the attribution graph captures only a fraction of the total computation. Each case study required several hours of analyst time to interpret. The tool doesn't capture attention pattern formation. At current scale, it couldn't be applied to the thousands-of-token reasoning chains modern models routinely produce.
And yet it already produces evidence that was not available before: a direct check on whether claimed reasoning steps are real; a mechanism for reliably inducing hallucinations that gives you a target to fix; a way to watch safety mechanisms lose out to competing pressures in real time.
Anthropic subsequently open-sourced the circuit-tracing tools.4 The interpretability team's stated longer-term goal is an AI system capable enough to accelerate the interpretability research itself — using AI to understand AI, at the scale that manual analysis can't reach.
The open question is whether the approach scales. Every capability jump in the underlying models adds complexity. The microscope that works on Claude 3.5 Haiku needs to evolve to keep pace. Whether interpretability can stay close enough to the frontier to matter is the live research question — and the answer will determine whether transparency tools like this remain a meaningful check on model behavior or become perpetually a few capability generations behind.
Loading content card…
Add more perspectives or context around this Post.